Live demo
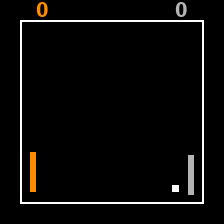
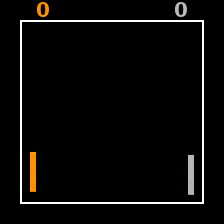
Live interaction with our 350M-parameter world model trained on 210 tasks. Control it with your keyboard! Our hallucination predictors run at every step; a red border indicates that a hallucination is detected.
Can you make the world model hallucinate?
checking…

Stable
WASDact
Spacepause
Rreset
Tap the on-screen keys to move, and tap the frame to pause.
stable
hallucination